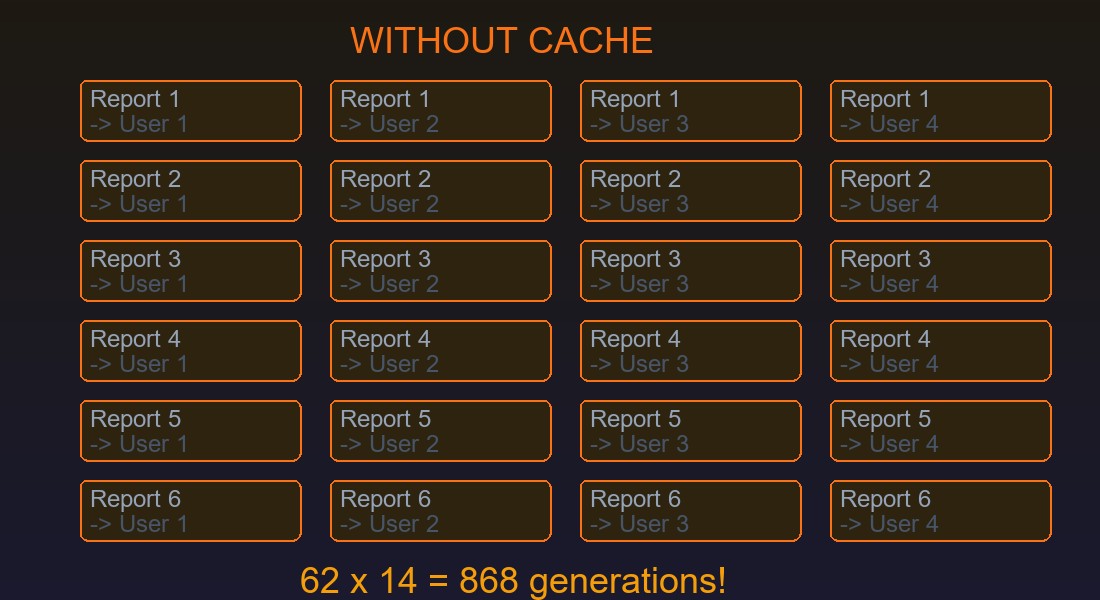
62 отчёта. 14 получателей. Каждое утро в 7:00 запускается рассылка, которая должна уложиться до начала рабочего дня. Должна -- но не укладывается. Двадцать минут -- и таймаут. Менеджеры приходят на работу, открывают почту -- а отчётов нет. Начинается день с вопросов, а не с цифр.
Это реальная задача, которую я решал для ресторанной группы. Несколько точек, ежедневные и еженедельные отчёты по каждой: выручка, списания, остатки, себестоимость. Все формируются в 1С и рассылаются по электронной почте через подсистему БСП "Рассылка отчётов". Звучит как типовая задача. На практике -- таймаут, жалобы, ручная отправка.
20 минут -- и таймаут
Рассылка работала так: регламентное задание запускалось по расписанию, формировало отчёты и отправляло их по списку получателей. На бумаге всё логично. На практике -- мучительно медленно.
Проблема стала заметна не сразу. Когда точек было три и получателей пятеро -- рассылка проскакивала за пару минут. Но бизнес рос. Добавлялись новые рестораны, новые отчёты, новые получатели. Постепенно время рассылки перевалило за 10 минут, потом за 15, а потом стало упираться в таймаут регламентного задания.
Менеджеры жаловались. Руководство нервничало. Бухгалтерия, получавшая те же отчёты что и управленцы, спрашивала: "А почему вчерашние данные пришли только к обеду?" Потому что после таймаута рассылка перезапускалась вручную -- когда кто-то замечал, что отчёты не пришли.
Временное решение было классическим: увеличить таймаут. Помогло на месяц. Потом добавили ещё две точки, и история повторилась. Увеличивать таймаут бесконечно нельзя -- регламентное задание блокирует ресурсы сервера, а утром на базу приходят пользователи. Нужно было не расширять горлышко, а убирать причину затора.
Один отчёт -- много получателей
Я полез в логи и замерил, сколько времени формируется каждый отчёт. Средний отчёт по выручке точки -- 15-20 секунд. Отчёт по себестоимости -- до 30 секунд. Суммарно на формирование всех 62 отчётов уходило порядка 18 минут. Отправка по почте -- секунды. Узкое место очевидно: не сеть, а формирование.
Но 62 -- это число отправок, а не число уникальных отчётов. Отчёт "Выручка по точке А за вчера" получают и управляющий этой точки, и финансовый директор, и собственник. Три получателя -- три формирования одного и того же отчёта. С одними и теми же параметрами. За один и тот же период. С идентичным результатом.
Посчитал: из 62 отправок уникальных комбинаций "отчёт + параметры" было 24. Остальные 38 -- повторы. Рассылка формировала один и тот же отчёт заново для каждого получателя, хотя результат не менялся. Это как печатать один и тот же документ на принтере 14 раз, вместо того чтобы напечатать один раз и сделать 13 копий.
Причина банальная. Подсистема рассылки БСП обрабатывает получателей последовательно: взять следующего получателя, определить его набор отчётов, сформировать каждый отчёт, прикрепить к письму, отправить, перейти к следующему. Архитектурно чисто и понятно. Но оптимизация под масштабирование не заложена -- это и не нужно для типовых сценариев, где отчётов пять и получателей двое.
Код рассылки устроен так, что для каждой записи в таблице получателей вызывается процедура формирования. Она честно открывает отчёт, устанавливает параметры, выполняет, сохраняет результат во временный файл. Потом файл прикрепляется к письму. После отправки -- удаляется. Следующий получатель -- та же процедура с нуля. Никакого кеша, никакого переиспользования. Каждый вызов -- как первый.
Кеш на уровне сеанса
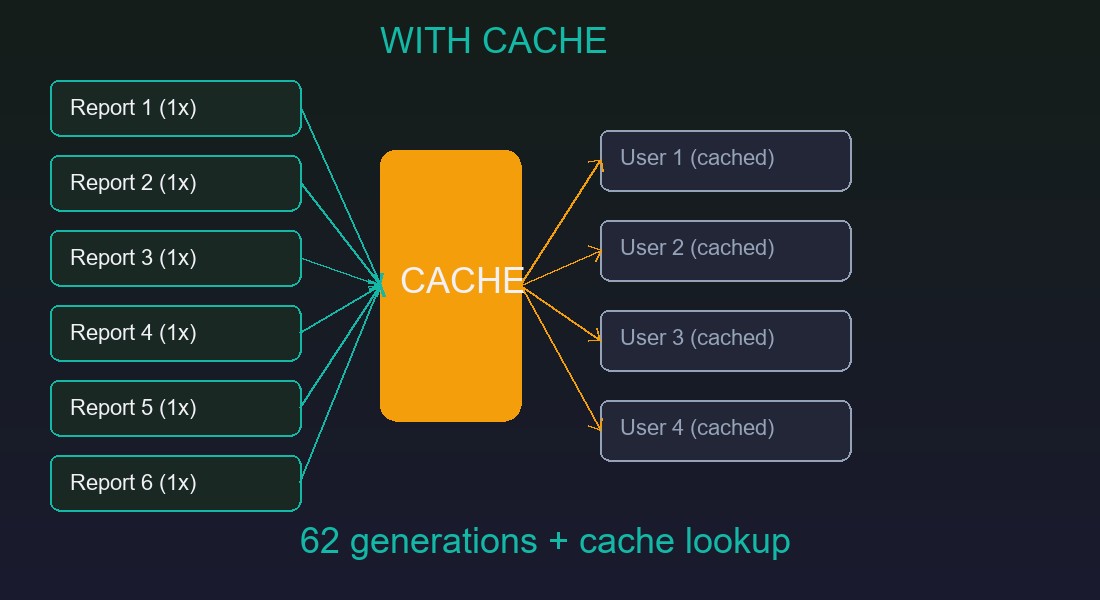
Решение напрашивалось: формировать каждый уникальный отчёт один раз и переиспользовать результат для всех получателей.
Реализовал через соответствие (Map) на уровне сеанса рассылки. Ключ -- хеш из идентификатора отчёта, варианта и набора параметров. Значение -- двоичные данные сформированного файла.
// Ключ кеша: уникальная комбинация отчёта и параметров
КлючКеша = СтрШаблон("%1_%2_%3",
Отчет.Метаданные().ПолноеИмя(),
КлючВарианта,
ХешПараметров);
// Проверяем кеш
Если КешОтчетов[КлючКеша] = Неопределено Тогда
// Формируем отчёт и кладём в кеш
РезультатОтчета = СформироватьОтчет(Отчет, Параметры);
КешОтчетов.Вставить(КлючКеша, РезультатОтчета);
КонецЕсли;
// Используем из кеша
ДвоичныеДанные = КешОтчетов[КлючКеша];Технически ничего сложного. Но дьявол, как водится, в деталях.
Первый нюанс: хеширование параметров. Параметры отчёта -- это не просто строки и числа. Там могут быть ссылки на справочники, периоды, массивы значений. Простое сравнение в лоб не работает -- нужно сериализовать параметры в строку и уже её хешировать. Я использовал ЗначениеВСтрокуВнутр() для параметров, а потом ХешированиеДанных для получения компактного ключа. Грубовато, но надёжно.
Второй нюанс: время жизни кеша. Кеш живёт ровно в пределах одного запуска рассылки. Запустилось регламентное задание -- создаётся пустое соответствие. Отработало -- соответствие ушло в мусор вместе с сеансом. Никакого глобального кеша, никаких проблем с устаревшими данными. Утренняя рассылка формирует отчёты за вчера. Вечерняя -- за сегодня. Пересечений нет.
Третий нюанс: память. 62 отчёта в виде Excel-файлов -- это от 50 до 200 KB каждый. Суммарно 24 уникальных отчёта в памяти -- порядка 3-5 MB. Для сервера с 16 GB оперативки это пыль. Но если бы отчёты были тяжёлыми (графики, сводные таблицы на сотни тысяч строк), потребовалось бы кешировать на диск, а не в память. В этом кейсе обошлось без усложнений.

Модификация затронула один модуль: обработку рассылки. Вместо прямого вызова формирования -- обёртка с проверкой кеша. Обратная совместимость полная: если отчёт запрашивается впервые, он формируется и кешируется; если повторно -- берётся из кеша. Внешний код ничего не знает о кешировании. Для него интерфейс не изменился.
Отдельно стоит сказать про порядок обхода получателей. Штатная рассылка обрабатывает их в произвольном порядке -- обычно по ключу записи в таблице. Это значит, что первый получатель может запросить отчёты A, B, C; второй -- D, E; третий -- снова A, B. Кеш работает в любом порядке, но я добавил предварительную сортировку: сначала получатели с наибольшим числом общих отчётов. Это не влияет на итоговое время (кеш всё равно сработает), но делает логи предсказуемыми: видно, что первые 24 формирования -- уникальные, а дальше идут чистые попадания в кеш. Отладка упрощается.
Был ещё один потенциальный подводный камень: параллельное выполнение. Если бы рассылка запускалась в нескольких фоновых заданиях одновременно (например, разные рассылки по расписанию совпали), каждое задание создало бы свой кеш. Пересечений между сеансами нет -- соответствие живёт в контексте одного вызова. Это и плюс (нет проблем с конкурентным доступом), и минус (если две рассылки формируют одинаковые отчёты, каждая сделает это самостоятельно). Для данного кейса это несущественно -- рассылка одна, запускается один раз утром. Но если бы рассылок было десять с пересекающимися отчётами, стоило бы подумать о межсеансном кеше через временное хранилище или файловую систему.
Подобный подход -- типичный пример того, как понимание внутренних механизмов 1С позволяет находить решения, которые не лежат на поверхности. Штатные средства СКД и рассылки работают корректно, но не оптимально для конкретного сценария.
Бонус: человекочитаемые имена файлов
Пока ковырялся в коде рассылки, заметил ещё одну вещь, которая раздражала получателей. Тема письма выглядела примерно так:
Рассылка отчётов: 00-000042А прикреплённый файл назывался:
Отчет_00-000042_20260312.xlsx00-000042 -- это внутренний код элемента справочника. Для 1С-ника понятно. Для управляющего ресторана -- абракадабра. Он получает пять писем с кодами и должен угадать, где выручка, а где себестоимость.
Исправил параллельно с кешированием. В теме письма и имени файла заменил коды на представления: наименование рассылки, наименование отчёта, период.
// Было:
ТемаПисьма = "Рассылка отчётов: " + Рассылка.Код;
ИмяФайла = "Отчет_" + Рассылка.Код + "_" + Формат(Дата, "ДФ=yyyyMMdd");
// Стало:
ТемаПисьма = СтрШаблон("Отчёты %1 за %2",
Рассылка.Наименование,
Формат(ДатаОтчета, "ДЛФ=Д"));
ИмяФайла = СтрШаблон("%1 — %2 (%3)",
ОтчетНаименование,
ТочкаНаименование,
Формат(ДатаОтчета, "ДЛФ=Д"));Теперь тема письма:
Отчёты Выручка по точкам за 12.03.2026А файл:
Выручка — Центральный за 12.03.2026.xlsxМелочь? Для разработчика -- да. Для человека, который получает эти письма каждый день -- разница между "опять эти коды" и "сразу вижу что пришло". Обратная связь от получателей была мгновенной: "О, наконец-то нормальные названия!"
Формально это не оптимизация производительности. Но это оптимизация пользовательского опыта, и она стоила пяти строк кода. Такие "бесплатные" улучшения стоит делать каждый раз, когда залезаешь в код по другому поводу.
Результат в цифрах
До оптимизации:
- 62 формирования отчётов (включая 38 повторных)
- Время рассылки: 18-22 минуты
- Регулярные таймауты, ручные перезапуски
- Нечитаемые темы писем и имена файлов
После оптимизации:
- 24 формирования отчётов (каждый уникальный -- один раз)
- Время рассылки: 4-5 минут
- Ноль таймаутов за три месяца эксплуатации
- Понятные темы писем и имена файлов
Ускорение в 4 раза. Причём это не предел -- при росте числа получателей выигрыш будет только увеличиваться. Если завтра добавят ещё пять человек в рассылку, количество формирований останется тем же -- 24. Вырастет только число отправок, а отправка письма -- миллисекунды.
Масштабируемость решения -- отдельный бонус. Через месяц после внедрения кеширования добавили две новые точки и три отчёта. Количество уникальных отчётов выросло с 24 до 31, а количество отправок -- с 62 до 89. Время рассылки увеличилось с 5 до 7 минут. Без кеширования было бы уже за 30 минут -- гарантированный таймаут. Кеш не просто решил текущую проблему, он обеспечил запас прочности на рост.
Стоимость решения: один рабочий день. Половина -- на анализ и профилирование, половина -- на реализацию и тестирование. Никаких инфраструктурных изменений, никаких миграций, никаких рисков. Один модуль, одна обёртка, одно соответствие в памяти.
Любопытно, что этот кейс -- зеркальное отражение типичной проблемы с запросами. Когда запрос к базе данных выполняется повторно с теми же параметрами, СУБД обычно кеширует план выполнения. Но на уровне прикладного кода 1С такого автоматического кеширования нет. Разработчик должен думать об этом сам. И часто не думает -- потому что "и так работает". До тех пор, пока не перестанет работать. Похожая история с LEFT JOIN и фильтрами в 1С: запрос формально корректный, но результат не тот, которого ожидаешь, и производительность проседает.
Главный вывод из этого кейса простой: прежде чем оптимизировать формирование отчёта (ускорять запросы, упрощать макет, менять структуру), стоит проверить -- а сколько раз он формируется. Может оказаться, что самый быстрый отчёт -- тот, который не нужно формировать заново.