Пустой список в конфиге значит «принимать всё». Так написано в документации blackbox_exporter. Так выглядит по логике YAML. Мониторинг показывает probe_success = 0.
Три предложения — три утверждения, из которых два ложных. А я потратил полдня, прежде чем разобрался в каком именно месте логика ломается.
Зачем мониторить 1С
У меня несколько production-баз на обслуживании. Узнавать о проблемах по звонку клиента — плохая практика. Хочу знать раньше: сервис упал, база недоступна, HTTP-сервис перестал отвечать. Желательно — до того, как это заметит бухгалтер.
Стек выбрал стандартный: Prometheus для сбора метрик, Grafana для визуализации, blackbox_exporter для внешних проверок доступности. Алерты — в Telegram.
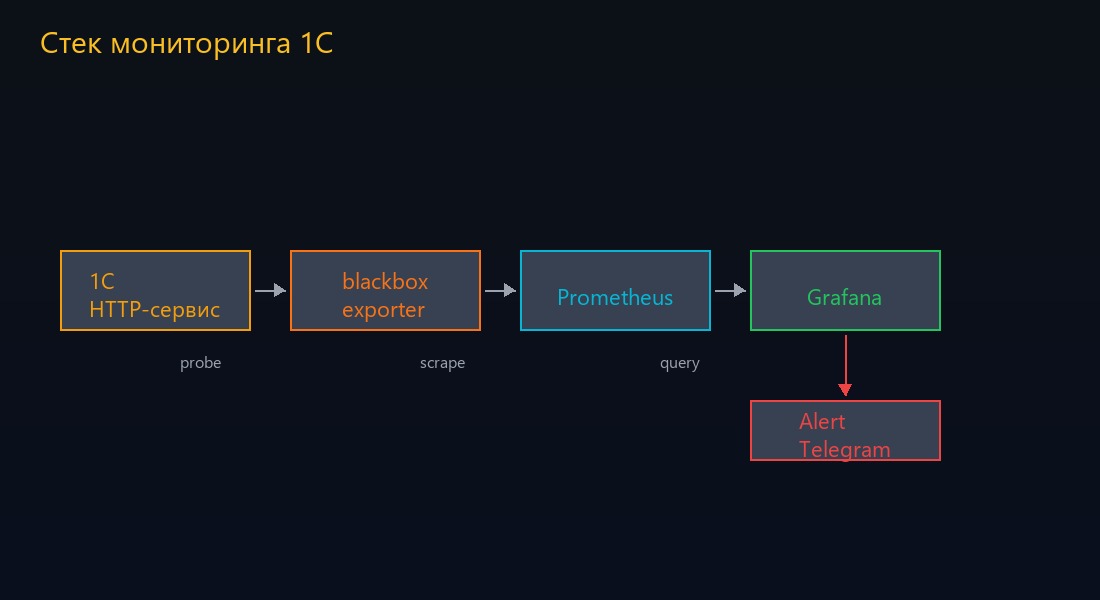
В каждой базе развёрнут HTTP-сервис — точка для health check. Blackbox_exporter стучит по URL, Prometheus собирает результат, Grafana показывает дашборд. Если probe_success = 0 дольше двух минут — алерт в Telegram.
Проблема: живой сервис помечен мёртвым
Настроил. Запустил. Все базы показывают probe_success = 0. Все «мёртвые». Включая ту, в которой я прямо сейчас работаю.
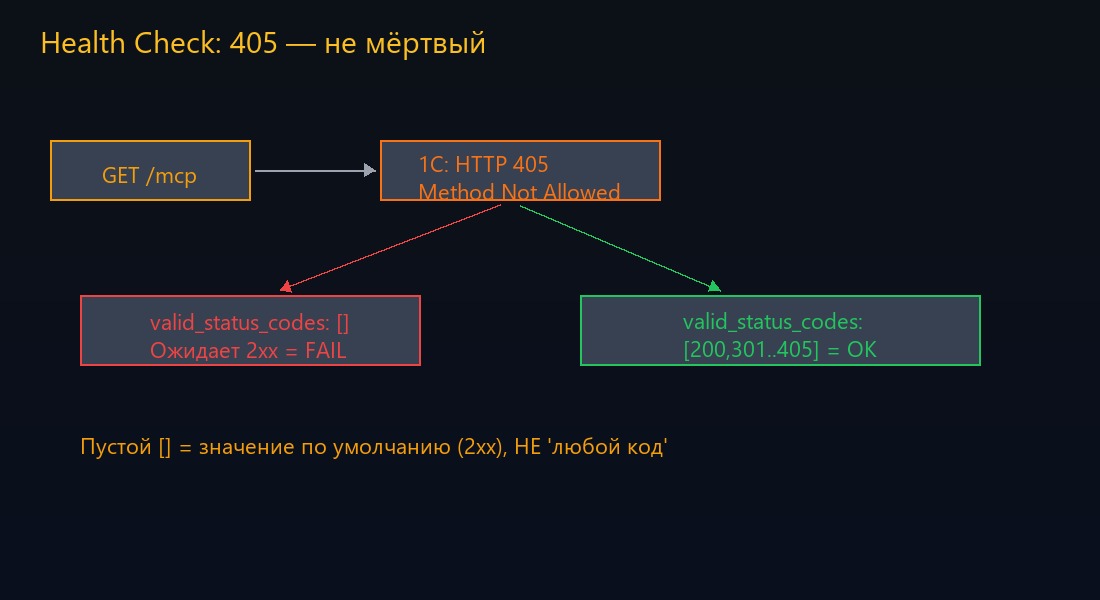
Проверяю руками. curl на тот же URL. Ответ мгновенный: HTTP 405, Method Not Allowed. Сервис жив, отвечает. Просто endpoint принимает только POST, а blackbox шлёт GET.
Для health check это нормально. Мне не нужен «правильный» ответ от бизнес-логики. Мне нужен факт: процесс слушает порт, HTTP-стек работает, соединение устанавливается. Код 405 говорит: «я тебя слышу, но ты стучишь не тем методом». Это признак жизни, не ошибки.
Ловушка пустого массива
Иду в конфиг blackbox_exporter. Модуль http_2xx, параметр valid_status_codes. Документация:
Accepted status codes for this probe. Defaults to 2xx.
Ставлю пустой список — по логике это должно означать «принимать любой код ответа». В YAML пустой массив — это отсутствие ограничений. Интуитивно. По аналогии с другими инструментами. По здравому смыслу.
probe_success = 0. По-прежнему.
Оказалось: пустой список valid_status_codes не означает «любой код». Он означает «значение по умолчанию». А по умолчанию — 2xx. Пустой массив и отсутствие параметра — одно и то же. Чтобы принять 405, нужно явно перечислить допустимые коды.
Документация не врёт. Но формулировка «Defaults to 2xx» не раскрывает, что пустой массив — это тоже default. Два часа на один параметр.
Решение: модуль http_alive
Создал отдельный модуль проверки с явным списком допустимых кодов:
modules:
http_alive:
prober: http
http:
valid_status_codes: [200, 301, 302, 400, 401, 403, 404, 405]
no_follow_redirects: true
preferred_ip_protocol: ip4
Логика простая. Разделяю понятия «сервис здоров» и «сервис жив»:
- 2xx — здоров. Работает как задумано
- 3xx, 4xx — жив. Процесс работает, HTTP-стек отвечает. Клиентская ошибка или редирект — не падение
- 5xx — проблема. Серверная ошибка, что-то пошло не так внутри
- Нет ответа — мёртв. Порт не слушает, процесс не запущен, сервер недоступен
Пятисотые коды оставил за пределами списка — они реальный сигнал проблемы. Всё остальное — признак жизни.
probe_success = 1. Алерт замолчал. Дашборд позеленел.
Настройка алертов в Telegram
Prometheus Alertmanager умеет отправлять в Telegram через webhook. Настраиваю правило:
groups:
- name: 1c_availability
rules:
- alert: 1CServiceDown
expr: probe_success == 0
for: 2m
labels:
severity: critical
annotations:
summary: "1С сервис недоступен: {{ $labels.instance }}"Два минуты — чтобы отсечь кратковременные сбои при деплое или перезагрузке. Если через две минуты сервис не ответил — это уже проблема, а не плановый рестарт.
В Telegram приходит чёткое сообщение: какой сервис, на каком хосте, сколько времени недоступен. Не «что-то упало» — а конкретная точка отказа.
Что мониторю сейчас
Помимо базового health check, со временем добавил несколько метрик:
- Время ответа HTTP-сервиса — если обычно отвечает за 50ms, а стал за 2 секунды, значит нагрузка растёт или деградация
- Количество активных сеансов — через
rac session list, парсю в Prometheus-формат. Резкий рост — кто-то нагенерировал фоновых заданий - Свободное место на диске — банально, но база 1С умеет вырасти на 10 GB за ночь, если пошли дубли в регистре
- Статус регламентных заданий — если фоновое задание обмена не отрабатывало больше часа, оно скорее всего зависло
Каждая метрика — это конкретная история из практики. Мониторинг сеансов появился после случая, когда обмен данными нагенерировал 200 фоновых заданий и база легла. Свободное место — после того, как журнал регистрации съел весь диск за выходные.
Итого
Prometheus + Grafana + blackbox_exporter — стек, который работает. Для 1С — не хуже, чем для любого другого сервиса. Но есть нюанс: 1С отвечает не совсем так, как ожидает стандартный мониторинг. HTTP 405 — это нормально. Пустой массив — это не «любой».
Разница между «сервис здоров» и «сервис жив» — один параметр конфига. Но чтобы его найти, нужно сначала перестать доверять пустым значениям.