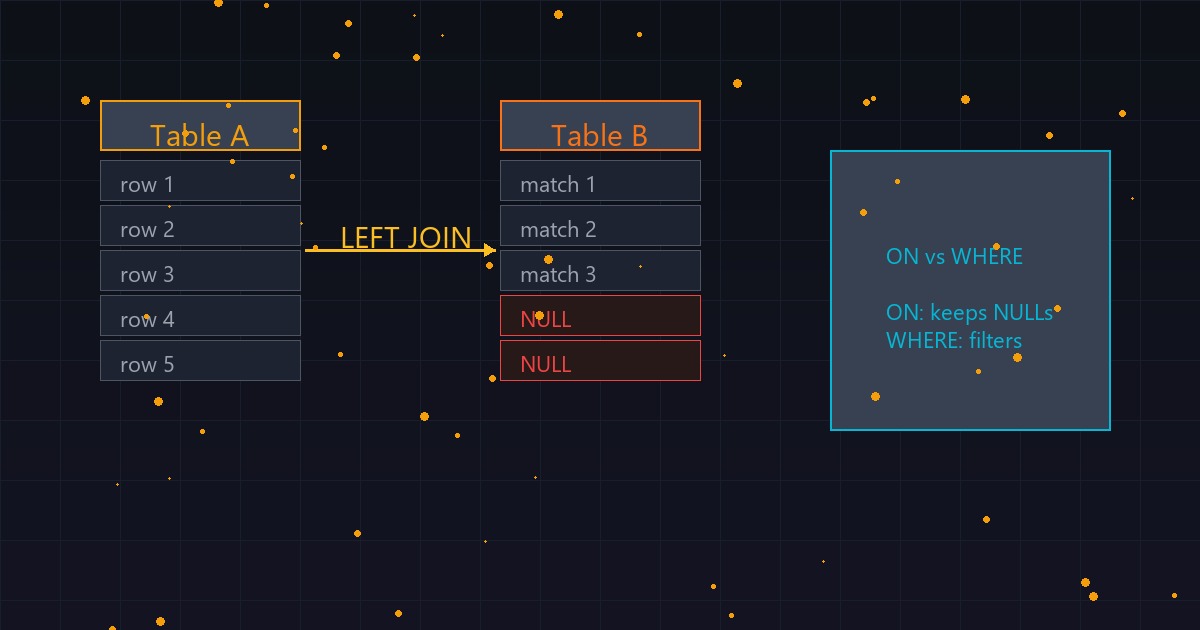
LEFT JOIN — одна из самых невинных конструкций в языке запросов 1С. Любой разработчик с полугодовым опытом напишет её правильно. Синтаксически правильно. А потом будет удивляться, почему отчёт за месяц формируется четыре минуты.
За семнадцать лет практики я видел десятки запросов, которые выглядели идеально и работали чудовищно. Почти всегда проблема была не в объёме данных, не в железе, не в индексах. Проблема была в понимании того, как SQL-сервер обрабатывает LEFT JOIN. Три истории ниже — из реальных проектов. Каждая про один и тот же оператор, но про разные ловушки.
История первая: отчёт 12-ТОРГ и фильтр не в том месте
Торговая сеть, бухгалтерия, конец месяца. Отчёт 12-ТОРГ — ежемесячная статистика розничных продаж: товарооборот по группам, наценка, реализация, себестоимость. Данные из нескольких регистров накопления. На выходе — пара тысяч строк. Рутина, которая не должна занимать больше десяти секунд.
Формировался четыре минуты.
Бухгалтер запускает отчёт, уходит за кофе, возвращается — ещё крутится. Со стороны «ну подождите, сложный отчёт». Но я-то знаю: несколько тысяч строк на выходе — это не сложный отчёт. Это медленный запрос.
Подозрение первое: виртуальная таблица
Основной запрос соединял виртуальную таблицу оборотов с регистром движений. В 1С параметры виртуальных таблиц — критичная точка для производительности. Если не указать период или условие отбора, платформа будет считать обороты по всей истории регистра. Классика жанра, первое место в списке «почему запрос тормозит».
Проверил. Параметры заданы корректно: период, организация, склады. Виртуальная таблица отрабатывает быстро. Не она.
План запроса
Открыл план запроса в SQL Server Management Studio. Table Scan на правой таблице — регистр движений общепита. Сотни тысяч строк читаются целиком. За нужный месяц там пара тысяч записей, но сервер читает всё. Фильтр по периоду стоит в запросе. Но не работает.
Фильтр по периоду стоял в ON-условии LEFT JOIN:
ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления.ДвиженияОбщепит КАК Общепит
ПО Обороты.Товар = Общепит.Товар
И Обороты.Склад = Общепит.Склад
И Обороты.Партия = Общепит.Партия
И Обороты.Организация = Общепит.Организация
И Общепит.Период >= &НачалоПериода
И Общепит.Период <= &КонецПериодаВыглядит логично. Соединяем по четырём полям и ограничиваем период. Синтаксически безупречно. Семантически — ловушка.
ON vs WHERE: один абзац в документации, четыре минуты ожидания
При INNER JOIN оптимизатор SQL Server может «протолкнуть» условие из ON внутрь таблицы. Сначала отфильтровать строки, потом соединять. Это называется predicate pushdown, и это одна из базовых оптимизаций.
При LEFT JOIN — нет. И причина фундаментальная.
LEFT JOIN гарантирует: каждая строка левой таблицы попадёт в результат. Если для неё нет пары в правой таблице — она получит NULL в правых столбцах. Это контракт оператора. Если оптимизатор заранее отфильтрует правую таблицу по периоду, часть строк левой таблицы потеряет свои пары и получит NULL вместо реальных значений. Результат запроса изменится. Оптимизатор не имеет права на такую подмену.
Поэтому он обязан прочитать все строки правой таблицы. Все периоды. Все организации. Все склады. И только потом, при соединении, проверить условия из ON.
А LEFT JOIN здесь выбран не случайно. Не все товары имеют движения по общепиту. Потерять их из статистики — значит получить неполный отчёт. INNER JOIN отбросит товары без пары. Это недопустимо.
Решение: временная таблица
Идея простая: разделить фильтрацию и соединение.
Первый запрос пакета: выбрать из регистра движений записи за нужный период, отфильтровать через WHERE по организации и складам, сгруппировать, положить во временную таблицу. Проиндексировать по ключу соединения.
ВЫБРАТЬ
Общепит.Товар,
Общепит.Склад,
Общепит.Партия,
Общепит.Организация,
СУММА(Общепит.Сумма) КАК Сумма
ПОМЕСТИТЬ ВТ_Общепит
ИЗ РегистрНакопления.ДвиженияОбщепит КАК Общепит
ГДЕ Общепит.Период >= &НачалоПериода
И Общепит.Период <= &КонецПериода
И Общепит.Организация = &Организация
СГРУППИРОВАТЬ ПО
Общепит.Товар, Общепит.Склад, Общепит.Партия, Общепит.Организация
;
ВЫБРАТЬ ...
ИЗ Обороты
ЛЕВОЕ СОЕДИНЕНИЕ ВТ_Общепит КАК Общепит
ПО Обороты.Товар = Общепит.Товар
И Обороты.Склад = Общепит.Склад ...WHERE в первом запросе работает до соединения. Оптимизатор свободен фильтровать, использовать индексы, отбрасывать ненужные строки. Во временную таблицу попадают только записи за нужный месяц. LEFT JOIN во втором запросе соединяется с компактной таблицей вместо сырого регистра.
Тридцать строк кода. Секунды вместо минут. Бухгалтер больше не ходит за кофе.
История вторая: точка через точку, или скрытые JOIN-ы
Крупная производственная компания, складской учёт. Отчёт по остаткам с детализацией до единицы измерения и ёмкости тары. Запрос простой, полей немного, данных — средне. Но работал в пять-шесть раз медленнее, чем ожидалось.
Смотрю текст запроса. Никаких явных LEFT JOIN. Никаких подзапросов. Обычный запрос к регистру с отбором. Откуда тормоза?
Точка — это JOIN
В списке полей стояли конструкции через точку:
ВЫБРАТЬ
Остатки.Номенклатура.Наименование,
Остатки.Номенклатура.ЕдиницаИзмерения.Наименование,
Остатки.Номенклатура.ЕдиницаИзмерения.Ёмкость,
Остатки.КоличествоОстаток
ИЗ РегистрНакопления.ТоварыНаСкладах.Остатки КАК ОстаткиЧетыре поля. Выглядит компактно. Но каждая точка — это неявное LEFT JOIN к таблице справочника. Платформа 1С автоматически разворачивает обращение через точку в соединение. Остатки.Номенклатура.ЕдиницаИзмерения.Ёмкость — это три соединения: регистр → справочник Номенклатура → справочник ЕдиницыИзмерения → поле Ёмкость.
И каждое такое соединение — LEFT JOIN. Потому что платформа не знает заранее, заполнена ли ссылка. Если ЕдиницаИзмерения пустая — строка не должна пропасть. Значит — LEFT JOIN. А мы уже знаем, что LEFT JOIN ограничивает оптимизатор.
Четыре поля через точку — это шесть скрытых LEFT JOIN к справочникам. Шесть соединений, о которых разработчик не думал, потому что не писал их руками.
Решение: явные соединения
Переписал запрос с явными LEFT JOIN:
ВЫБРАТЬ
Номенклатура.Наименование,
Единица.Наименование,
Единица.Ёмкость,
Остатки.КоличествоОстаток
ИЗ РегистрНакопления.ТоварыНаСкладах.Остатки КАК Остатки
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.Номенклатура КАК Номенклатура
ПО Остатки.Номенклатура = Номенклатура.Ссылка
ЛЕВОЕ СОЕДИНЕНИЕ Справочник.ЕдиницыИзмерения КАК Единица
ПО Номенклатура.ЕдиницаИзмерения = Единица.СсылкаДва явных соединения вместо шести неявных. Платформа больше не генерирует дублирующие JOIN к одной и той же таблице. Оптимизатор видит ясную структуру и строит эффективный план.
Ускорение — в пять-шесть раз. На тех же данных, на том же сервере. Только за счёт того, что я написал руками то, что платформа генерировала автоматически (и плохо).
Самое обидное: этот запрос писал грамотный разработчик. Он знал про параметры виртуальных таблиц, про индексы, про ЕСТЬNULL. Но точечная нотация настолько органична для языка запросов 1С, что вопрос «а во что это превращается на уровне SQL?» просто не возникает. Платформа делает вид, что обращение через точку — это обращение к свойству объекта. На самом деле это JOIN. И не один.
Правило, которое я вывел для себя: одна точка — допустимо. Две точки и больше — повод переписать на явные соединения. Особенно если запрос работает с таблицами, где больше десяти тысяч строк.
История третья: период в ON и полный скан
Ресторанная группа, учёт продуктов. Отчёт по списанию за период: для каждого блюда — расход ингредиентов, остатки, себестоимость. Запрос соединяет таблицу рецептур с регистром движений. LEFT JOIN, потому что не все блюда имели движения за период — и такие позиции нужно показать с нулевым расходом.
Знакомая ситуация. И знакомая ошибка: фильтр по периоду стоял в ON-условии.
ЛЕВОЕ СОЕДИНЕНИЕ РегистрНакопления.РасходПродуктов КАК Расход
ПО Рецепт.Ингредиент = Расход.Номенклатура
И Расход.Период >= &Начало
И Расход.Период <= &КонецТа же механика, что в первой истории. Оптимизатор не может протолкнуть фильтр по периоду внутрь правой таблицы. Полный скан регистра движений. Сотни тысяч строк. Ресторанная группа с десятками точек и тысячами наименований — регистр накопил данные за годы.
Но есть нюанс
В этом случае простое вынесение фильтра в WHERE не работает. Потому что WHERE применяется после соединения, и строки без пары (с NULL в правой части) будут отброшены условием Расход.Период >= &Начало. NULL не больше и не меньше любой даты — NULL не равен ничему. WHERE уничтожит именно те строки, ради которых выбран LEFT JOIN.
Это вторая ловушка, зеркальная первой. В первой истории фильтр в ON не работает для оптимизации. Здесь фильтр в WHERE работает, но меняет логику запроса. Оба варианта — неправильные.
Решение: снова временная таблица
Тот же паттерн, что и в первой истории. Выносим правую таблицу во временную, фильтруем через WHERE, индексируем по ключу соединения:
ВЫБРАТЬ
Расход.Номенклатура,
СУММА(Расход.Количество) КАК Количество,
СУММА(Расход.Сумма) КАК Сумма
ПОМЕСТИТЬ ВТ_Расход
ИЗ РегистрНакопления.РасходПродуктов КАК Расход
ГДЕ Расход.Период >= &Начало
И Расход.Период <= &Конец
СГРУППИРОВАТЬ ПО Расход.Номенклатура
ИНДЕКСИРОВАТЬ ПО Номенклатура
;
ВЫБРАТЬ
Рецепт.Блюдо,
Рецепт.Ингредиент,
ЕСТЬNULL(Расход.Количество, 0) КАК РасходКоличество,
ЕСТЬNULL(Расход.Сумма, 0) КАК РасходСумма
ИЗ Рецептуры КАК Рецепт
ЛЕВОЕ СОЕДИНЕНИЕ ВТ_Расход КАК Расход
ПО Рецепт.Ингредиент = Расход.НоменклатураВременная таблица содержит только данные за нужный период. LEFT JOIN к ней работает быстро — таблица компактная и проиндексированная. Логика сохранена: блюда без движений получат NULL (обёрнутый в ЕСТЬNULL).
Результат: с полутора минут до двух секунд. При объёме регистра в четыреста тысяч записей разница между полным сканом и выборкой за месяц — два порядка.
Паттерн, который объединяет все три истории
Одна и та же ошибка в трёх вариациях: разработчик думает о логике запроса, но не о механике его выполнения.
Первая история — фильтр в ON вместо предварительной выборки. Разработчик пишет условие там, где оно читается логично, не задумываясь о том, что оптимизатор не может его использовать.
Вторая история — точка через точку вместо явных соединений. Платформа 1С прячет сложность за удобным синтаксисом. Разработчик пишет одну строку — а SQL-сервер выполняет шесть соединений.
Третья история — снова фильтр в ON, но с дополнительной ловушкой: очевидный «фикс» (перенос в WHERE) ломает логику. Правильное решение — не перенести условие, а изменить архитектуру запроса.
Общий паттерн решения — временные таблицы. Выбрать данные с фильтрацией через WHERE, сгруппировать, проиндексировать, и уже потом соединять. Это на десять-двадцать строк длиннее, чем «в лоб». Но разница между секундами и минутами стоит этих строк.
Что стоит проверить в своих запросах
Несколько признаков, что запрос может иметь проблему с LEFT JOIN:
- В ON-условии LEFT JOIN есть фильтр по периоду, организации или другому полю, не являющемуся ключом соединения. Это не условие связи — это условие фильтрации, и оно не работает так, как вы ожидаете.
- В тексте запроса есть обращения через две и более точки:
Таблица.Поле.Подполе.ЕщёПодполе. Каждая точка — потенциальный скрытый LEFT JOIN. - Запрос использует LEFT JOIN к таблице с большим объёмом данных (регистры накопления, регистры сведений с историей). Если нет предварительной фильтрации — будет полный скан.
- В плане запроса SQL Server видны Table Scan или Clustered Index Scan на таблицах, которые должны фильтроваться по индексированным полям. Сканирование вместо поиска — верный признак того, что оптимизатор не смог протолкнуть условие.
Проверка занимает десять минут. Исправление — полчаса. Эффект — десятикратное ускорение на реальных данных. Арифметика, которая всегда сходится.
WHERE ограничивает данные до соединения. ON определяет правило самого соединения. Одно ключевое слово. В документации по SQL — абзац. В ежемесячном отчёте — четыре минуты, пока бухгалтер ждёт.