Звонок в понедельник утром. Клиент говорит: нужно добавить новый тип документов в обработку HTTP-сервиса. Я открываю модуль и вижу 2400 строк в одной процедуре. Не в модуле -- в одной процедуре. Гигантский switch-case на типы документов: чеки ККМ, перемещения между точками, заказы интернет-магазина, РКО, учет рабочего времени. Всё в одном месте, переплетённое общими переменными и копипастой.
Добавить новый тип? Технически -- да, ещё одну ветку в эту конструкцию. Практически -- я не могу гарантировать, что не сломаю то, что уже работает. Когда функция занимает 2400 строк, никто не держит в голове все её состояния. Даже автор. Тем более -- через полгода после написания.
Я сказал клиенту: прежде чем добавлять новое, нужно привести в порядок старое. Иначе каждая следующая доработка будет дороже предыдущей. И рискованнее.

Момент, когда понял -- пора
Этот модуль жил в production больше года. Работал? Да. Заказы обрабатывались, чеки пробивались, перемещения проводились. С точки зрения бизнеса -- всё отлично. С точки зрения кода -- бомба замедленного действия.
Я сталкивался с этим модулем и раньше. Каждый раз, когда нужно было что-то поправить, уходило непропорционально много времени. Найти нужный фрагмент -- десять минут скроллинга. Понять контекст -- ещё полчаса: какие переменные к этому моменту уже инициализированы, какие ещё нет, что будет, если вот эта ветка условия не выполнится. Внести правку -- пять минут. Убедиться, что ничего не сломал -- час ручного тестирования.
Но последней каплей стала не сложность доработки. Последней каплей стал BSL Language Server -- линтер для языка 1С, который я подключил к проекту в рамках настройки CI/CD пайплайна. Линтер выдал на этот модуль 47 предупреждений. Среди них -- циклическая сложность 369. Я перечитал дважды. Триста шестьдесят девять.
Для контекста: порог предупреждения в BSL -- 20. Порог ошибки -- 50. У меня было 369. В семь раз больше уровня ошибки. Это не просто сложный код. Это код, который физически невозможно тестировать полностью: количество уникальных путей выполнения измеряется сотнями.
В тот момент я перестал уговаривать себя, что «работает -- не трогай». Трогать придётся. И чем позже -- тем дороже.
Циклическая сложность 369 -- что это значит на практике
Циклическая сложность (Cyclomatic Complexity, CC) -- метрика Томаса Маккейба из 1976 года. Считает количество линейно независимых путей через код. Каждый Если, каждый Цикл, каждый Попытка добавляет единицу к CC. Простая функция без ветвлений -- CC=1. Функция с одним Если/Иначе -- CC=2.
CC=369 означает 369 различных путей выполнения через одну процедуру. Чтобы протестировать все ветки, нужно 369 тест-кейсов. Ни один разработчик не напишет столько. Ни один QA не проверит столько вручную. Значит, какие-то пути никогда не тестировались. Какие-то комбинации условий никогда не возникали в production. Пока не возникали.
На практике CC=369 проявляется так:
- Отладка превращается в квест. Ставишь точку останова -- и проходишь через 15 уровней вложенных
Если, прежде чем добираешься до нужного места. Причём путь зависит от данных: с другим набором документов отладчик пойдёт совсем другой дорогой. - Правки в одном месте ломают другое. Переменная, объявленная на строке 120, используется на строке 2300. Между ними -- 2180 строк кода, в которых эта переменная может быть переприсвоена в любой из 50 веток. Меняешь инициализацию -- и где-то далеко внизу логика ломается.
- Code review невозможен. Я не могу попросить коллегу проверить правку в этом модуле. Чтобы понять контекст одной строки, нужно прочитать все 2400. Никто этого не сделает. Ревью превращается в формальность: «ну, выглядит нормально».
- Баги прячутся в комбинациях. Каждая ветка по отдельности корректна. Но когда ветка A устанавливает переменную, а ветка B через 500 строк проверяет её, не зная о ветке C, которая между ними переписывает значение -- получаешь баг, который воспроизводится только на определённых данных в определённой последовательности. Знакомая ситуация? Про похожий случай с взаимными масками багов я написал отдельный разбор.
Когда я показал клиенту число 369, он спросил: «Это много?» Я ответил: «Рекомендованный максимум -- 20. У вас в 18 раз больше». Дальше уговаривать не пришлось.
Стратегия разбиения
Рефакторинг монолитного модуля -- не творческий процесс. Это инженерная задача с конкретными шагами. Вот как я действовал.
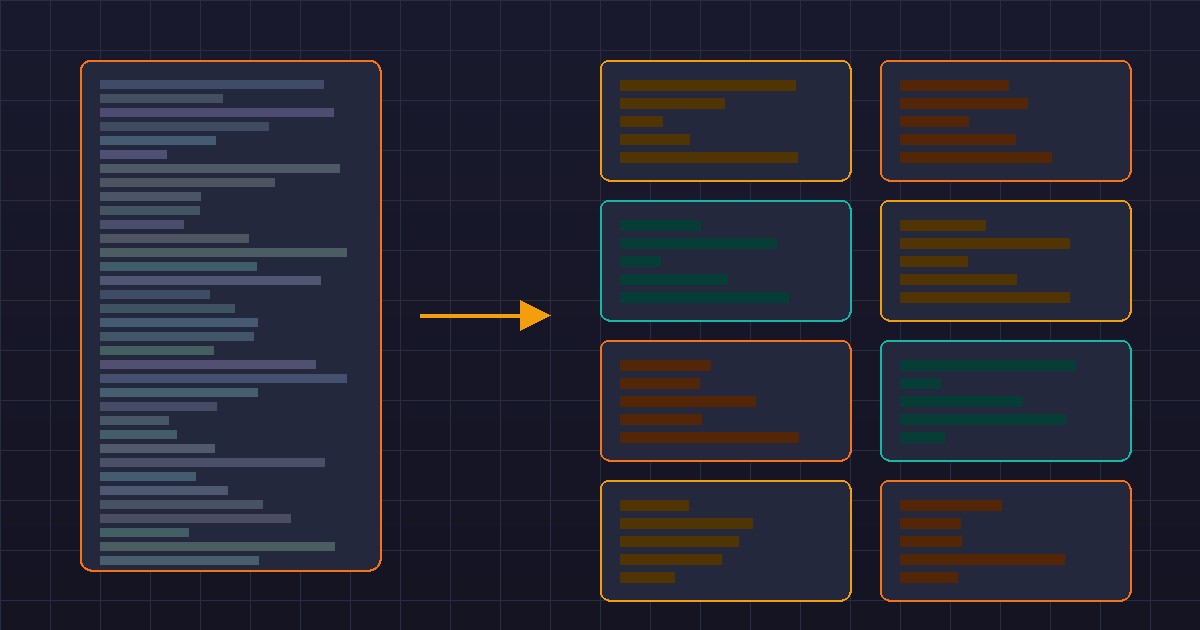
Шаг 1. Карта ответственностей. Я прочитал все 2400 строк (да, целиком, с блокнотом) и выписал, какие типы документов обрабатывает процедура. Получилось пять основных типов:
- Чеки ККМ -- пробитие и возврат
- Перемещение товаров на другую точку
- Перемещение товаров с другой точки
- Заказы интернет-магазина
- Расходные кассовые ордера
- Учет рабочего времени
Плюс два сквозных куска логики, которые использовались в нескольких типах: поиск единицы прослеживаемости (для маркированных товаров) и распределение по партиям (FIFO).
Шаг 2. Определение границ. Для каждого типа документов я выделил: входные данные (что приходит в HTTP-запросе), выходные данные (что возвращается в ответе), какие объекты базы создаются/изменяются. Это дало мне контракты будущих функций.
Шаг 3. Выделение хелперов. Поиск единицы прослеживаемости и распределение по партиям -- это чистые функции. Они не зависят от типа документа. Принимают данные, возвращают результат, не меняют состояние. Их я вынес первыми, потому что это безопасно: вызывающий код не менялся по логике, менялся только адрес вызова.
Функция НайтиЕдиницуПрослеживаемости принимает номенклатуру и характеристику, возвращает единицу прослеживаемости или пустую ссылку. Раньше этот код дублировался в трёх местах модуля с минимальными отличиями. Теперь -- одна функция, три вызова.
Функция РаспределитьПоПартиям реализует FIFO-распределение: принимает таблицу товаров и остатки по партиям, возвращает таблицу с распределением каждой строки по конкретным партиям. Алгоритм FIFO -- первая поступившая партия списывается первой. Логика непростая, 180 строк, но замкнутая: ей не нужно знать, чек это или перемещение.
Шаг 4. Выделение обработчиков по типам. Каждый тип документа стал отдельной функцией:
// Было: одна процедура 2400 строк
Процедура ОбработатьЗапрос(Запрос)
Если ТипДокумента = "ЧекККМ" Тогда
// 400 строк
ИначеЕсли ТипДокумента = "ПеремещениеНа" Тогда
// 350 строк
ИначеЕсли ...
КонецЕсли;
КонецПроцедуры
// Стало: диспетчер + 8 функций
Процедура ОбработатьЗапрос(Запрос)
ТипДокумента = ОпределитьТипДокумента(Запрос);
Если ТипДокумента = "ЧекККМ" Тогда
Результат = ОбработатьЧекиККМ(ДанныеЗапроса);
ИначеЕсли ТипДокумента = "ПеремещениеНа" Тогда
Результат = ОбработатьПереносНаДругуюТочку(ДанныеЗапроса);
ИначеЕсли ТипДокумента = "ПеремещениеС" Тогда
Результат = ОбработатьПереносСДругойТочки(ДанныеЗапроса);
ИначеЕсли ТипДокумента = "ЗаказИМ" Тогда
Результат = ОбработатьЗаказИМ(ДанныеЗапроса);
ИначеЕсли ТипДокумента = "РКО" Тогда
Результат = ОбработатьРКО(ДанныеЗапроса);
ИначеЕсли ТипДокумента = "УчетРВ" Тогда
Результат = ОбработатьУчетРВ(ДанныеЗапроса);
КонецЕсли;
Возврат СформироватьОтвет(Результат);
КонецПроцедурыДиспетчер -- 30 строк. Каждый обработчик -- 200-400 строк. Всё еще не идеально, но каждая функция делает одну вещь, и её CC в пределах нормы.
Шаг 5. Параллельная работа тестов. После каждого выделения функции я прогонял существующие интеграционные тесты. Не юнит-тесты -- их не было и нет (наследие). Интеграционные: отправить HTTP-запрос, проверить, что в базе создались правильные документы. Грубо, медленно, но надёжно. Если после выделения функции тесты зелёные -- двигаемся дальше. Красные -- откатываемся и ищем ошибку.
Весь рефакторинг занял три рабочих дня. Не потому что технически сложно -- потому что каждый шаг нужно было проверить. Спешка при рефакторинге обходится дороже, чем сам рефакторинг.
BSL линтер: борьба с ложными срабатываниями
Параллельно с рефакторингом я чистил предупреждения BSL линтера. И столкнулся с проблемой, которая стоила мне полдня.
CreateQueryInCycle -- правило, которое находит создание объектов Новый Запрос внутри циклов. Обоснованное правило: создание запроса в цикле -- это почти всегда антипаттерн. Каждая итерация -- обращение к СУБД. Десять итераций -- десять запросов вместо одного. Это убивает производительность.
Линтер нашёл 10 нарушений CreateQueryInCycle в модуле. Я начал исправлять: выносить создание запросов из циклов, передавать параметры через Запрос.УстановитьПараметр(), в некоторых случаях заменять цикл с запросами на один запрос с В (&СписокЗначений). 298 строк изменений -- серьёзный объём. Каждое исправление проверял тестами.
Но два из десяти нарушений были ложными. Запрос создавался в цикле намеренно: в каждой итерации он обращался к разным таблицам (имя таблицы формировалось динамически). Вынести такой запрос из цикла невозможно -- у него на каждой итерации другой текст.
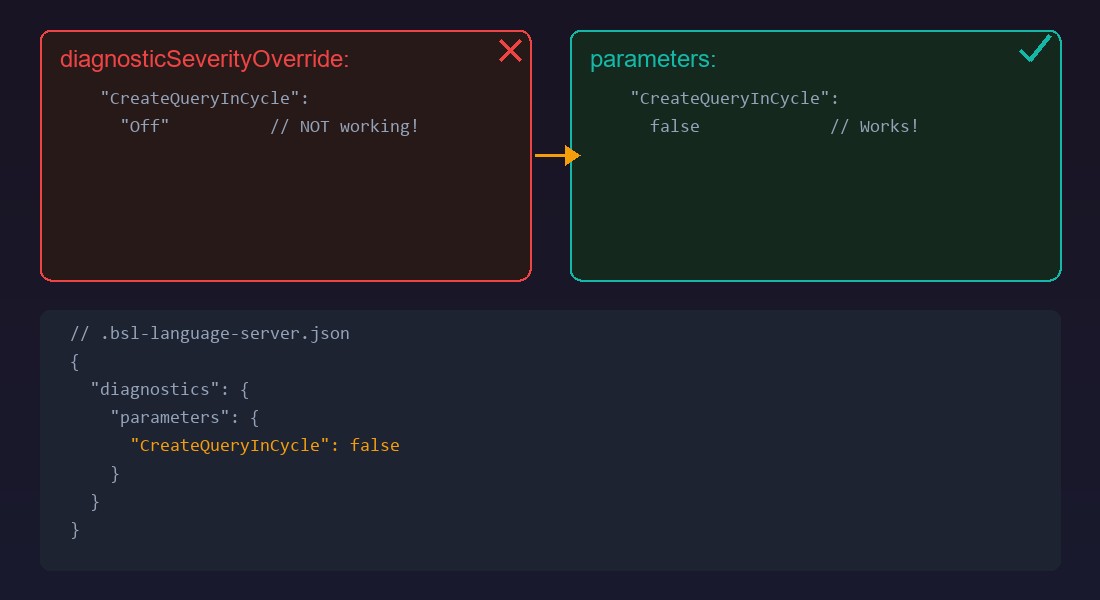
Логичное решение -- подавить предупреждение для этих двух мест. В документации BSL описан механизм diagnosticSeverityOverride в конфигурационном файле .bsl-language-server.json. Идея: переопределить severity конкретного правила, например, поставить OFF. Но мне нужно было не отключить правило глобально, а подавить его в конкретных местах.
Попробовал diagnosticSeverityOverride для точечного подавления -- не работает. Формат описан в документации, но на практике BSL Language Server его игнорирует для отдельных вхождений. Потратил два часа на эксперименты с разными вариантами синтаксиса, перечитал issues на GitHub.
Решение нашлось в другом месте конфига. Вместо diagnosticSeverityOverride нужно использовать секцию parameters с явным указанием значения false для конкретного правила в конкретном контексте. Выглядит так:
// .bsl-language-server.json
{
"diagnostics": {
"parameters": {
"CreateQueryInCycle": false
}
}
}Но это отключает правило полностью. Мне нужно было оставить его активным для всего кода, кроме двух конкретных мест. Финальное решение -- комбинация: правило включено глобально, а в двух проблемных местах -- inline-подавление через комментарий:
// BSLLS:CreateQueryInCycle-off
Запрос = Новый Запрос;
Запрос.Текст = СформироватьТекстЗапроса(ИмяТаблицы);
// BSLLS:CreateQueryInCycle-onInline-подавление через комментарии // BSLLS:{ИмяПравила}-off/on -- вот что реально работает для точечного отключения. Документация по diagnosticSeverityOverride описывает глобальное переопределение, но для файлового или построчного уровня нужен именно этот синтаксис.
Урок для тех, кто начинает работать с BSL линтером: не верьте документации буквально. Проверяйте на практике. И читайте issues на GitHub проекта -- там реальные решения от реальных пользователей, а не идеализированные примеры.
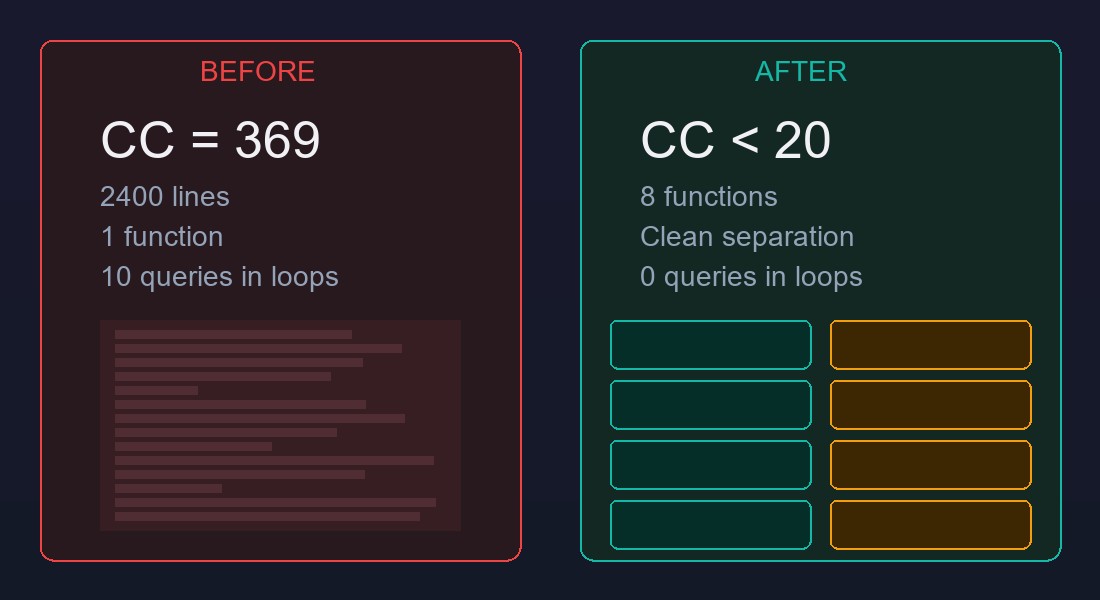
Результаты
Сухие цифры:
| Метрика | До | После |
|---|---|---|
| Количество функций | 1 | 8 + 2 хелпера |
| Максимальная длина функции | 2400 строк | 380 строк |
| Циклическая сложность (макс.) | 369 | 18 |
| CreateQueryInCycle нарушения | 10 | 0 (2 подавлены осознанно) |
| Общий объём изменений | -- | ~600 строк рефакторинг + 298 строк запросы |
Но цифры -- это формальность. Вот что изменилось на практике.
Новый тип документа добавился за два часа. Тот самый, ради которого всё начиналось. Я создал функцию ОбработатьНовыйТип, добавил ветку в диспетчер, написал тест. Два часа вместо «не знаю сколько, и не уверен, что не сломаю остальное».
Баги стали локализуемыми. Через неделю после рефакторинга прилетел баг: неправильно считались партии при перемещении. Я открыл ОбработатьПереносНаДругуюТочку -- 280 строк. Нашёл проблему за 15 минут. В старом монолите это заняло бы час-два: сначала найди, где вообще обрабатываются перемещения, потом разберись в контексте.
Code review стал реальным. Коллега может прочитать функцию в 300 строк и дать осмысленный фидбек. 2400 строк -- нет. Это не вопрос лени. Это вопрос рабочей памяти: человек удерживает в голове 7 плюс-минус 2 объекта. В функции на 300 строк -- десяток переменных и три-четыре ветки. В монолите на 2400 -- сотня переменных и десятки веток. За пределами человеческих возможностей.
Дублирование исчезло. Поиск единицы прослеживаемости был скопирован в трёх местах. Одна копия содержала ошибку, которую исправили год назад. Другая -- не содержала. Исправление дошло до одной копии, но не до остальных. Классика копипасты. Теперь -- одна функция НайтиЕдиницуПрослеживаемости, одно место для правок.
FIFO-распределение стало тестируемым. Когда РаспределитьПоПартиям -- отдельная функция с чётким контрактом (вход: таблица товаров + остатки; выход: таблица с распределением), её можно покрыть юнит-тестами. Подготовил данные, вызвал функцию, проверил результат. Без создания HTTP-запроса, без инициализации всего HTTP-сервиса. Тест выполняется за секунду вместо тридцати.
Но главный результат -- психологический. Раньше каждая доработка этого модуля вызывала тревогу: а вдруг сломаю? Теперь доработка -- рутина. Открыл нужную функцию, внёс изменение, прогнал тесты. Без страха, без многочасовой перестраховки.
Рефакторинг -- это не про красоту кода. Это про управляемость. Монолит на 2400 строк -- неуправляемый. Его нельзя безопасно менять, нельзя тестировать, нельзя ревьюить. Восемь функций по 200-400 строк -- управляемые. Каждая понятна, каждая тестируема, каждая заменяема.
Три дня рефакторинга против года мучений при каждой доработке. Окупается за первую же задачу.
Кстати, если вы тоже работаете с HTTP-сервисами и интеграциями в 1С -- обратите внимание на типичные проблемы с API БСП. Когда модуль вызывает функции БСП, а те молча возвращают не то, что ожидаешь -- отлаживать монолит становится втройне веселее. Ещё один аргумент за мелкие функции: чем меньше контекст, тем проще найти, кто именно вернул ерунду.